😬 The $1T Slack Message Slip Up

Ever pirated a song?
Or maybe grabbed a book or essay online to “save time” in college?
Are your streaming services in order or does your cousin still sign in once and a while?
No judgement.
We’ve all had a *Napster/Limewire *moment at some point.
Hell, in the 90's I used to run an FTP server on Windows 98 with a DSL connection.
**But here’s the difference: **when individuals do it, it’s a slap on the wrist.
When an AI company does it at scale? That’s a billion-dollar lawsuit waiting to happen.
This week, we’re getting into the copyright showdown that could reshape the AI landscape, featuring Anthropic, a Slack message that aged like warm milk, and a ghost library that just won’t stay buried.
Let’s talk datasets, damage control, and the very expensive lesson in “what not to do” with pirated content.
📚 Anthropic and the Pirate Library Problem
A single weekend data grab now threatens to drain one of the most valuable AI start-ups on earth.
Key Facts
📖 Almost every living U.S. author is suing Anthropic for copyright infringement.
💸 Potential damages range from $1.5 billion to over $1 trillion, depending on how the jury views it.
⏳ The trial is set for December 2025, a date AI companies are watching closely.
Last year, a few Anthropic engineers spotted a full mirror of Z-Library.
ℹ️ A “Z-Library” is a shadow library website that hosts millions of pirated books and academic articles. It’s been a go-to source for free (but unauthorized) downloads, and a legal headache for publishers and copyright holders.
They downloaded it, tucked it into training buckets, and left the copies sitting on servers after model runs finished.
A Slack message from a co-founder “zlibrary my beloved” now headlines the evidence list.
Judge William Alsup has drawn a clear line:
✅ Scanning books you bought for fresh digital versions = acceptable fair use.
❌ Keeping pirate copies after training = likely infringement.
I remember a few months ago, the girls and I went for a stroll in the Uptown district close to home after dinner.We popped into a few stores, one of them was a vintage book store.
It was nostalgic and fun flipping through some yellowed paperbacks. Some of them as low as about three bucks.
Those same titles may soon appear on an exhibit list, each one priced at $750 in statutory damages.
The contrast is wild.
$3.00 to bring the original home vs. Anthropic may pay three-quarters of a grand for the same story.
💥 The numbers that sting
Anthropic’s valuation is $150B, but most of that is cloud credits, not cash.
If they’re found liable for training on 2 million pirated books, they could owe $1.5 billion in damages (that’s $750 per book, per copyright law). That alone might exceed what they have on hand.
And if they want to appeal? They’ll likely need to post a nine-figure bond, which could mean scrambling for fresh funding or selling off assets while a max theoretical could exceed $1 trillion.
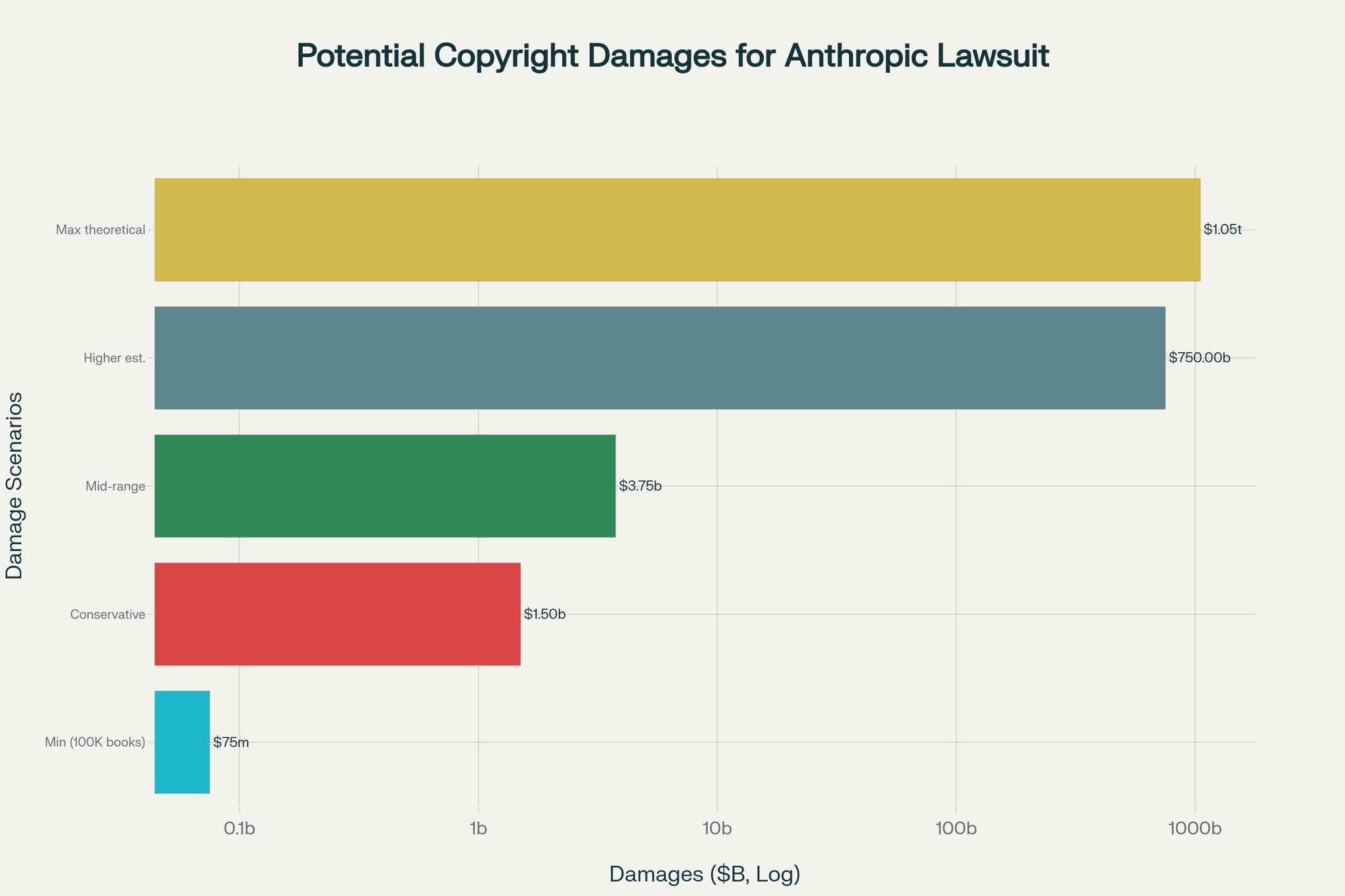 Shout out to Perplexity for making the above chart for me :)
Shout out to Perplexity for making the above chart for me :)
Meta faced a similar lawsuit but dodged it on a technicality.
Not because their practices were cleaner, just luckier.
That uneven outcome could reshape competition faster than any model upgrade.
While you're likely not playing at the same level as Anthropic, it's a good time to remember that what we train our AI models on matter.
So what you can do to avoid a similar lawsuit?
Identify datasets that would cripple operations if use rights vanished. Create that list today.
Gather proof of ownership or licenses for every data source. Store it with the same rigor as financial statements.
Replace antagonism with partnership when possible. A revenue-sharing license often costs less than discovery fees.
Finish those steps and you can walk into the next investor call with confidence instead of anxiety.
👀 Did you see this?
Last week, we discovered something very impactful.There was a checkbox next to the ability to share a chat from ChatGPT's interface that made a conversation discoverable.
Thousands upon thousands of chats intended to be private had mistakenly been shared and indexed by Google.

It's important that no matter what we share online, where privacy is open, we remain vigilant and trust these links as far as we can throw them. 👀
💻 Try This Prompt
Over the weekend, I was studying more about Ikigai and remembered the fact that I never fully finished the process because of how much dedicated space and time I needed.
Copy and paste this prompt into your favorite LLM of choice that knows the most about you and see what it comes up with. You might just be blown away
> Based off everything you know about me, think, evaluate and reason my true Ikigai. Then explain your answer in detail, justifying the decision without doubt.
✌️ Let's Talk
This is the part where I say: don’t wait for the lawsuit.
If you’re training models, building tools, or even just testing ideas, your data deserves the same scrutiny as your finances. Especially when one Slack message can cost you $1.5B.
And hey, if you want help building smarter systems before a judge gets involved, catch me in Slack.
See you out there. Stay curious, stay careful, and remember: a clean dataset is a beautiful thing.
Enjoy this edition?
Get CTRL+ALT+BUILD™ delivered to your inbox every week.